Tutorial on normalizing flows, part 1

Before we start, I would like to mention that this blog post assumes a familiarity with generative models and modern deep learning techniques.
Furthermore, if you would like to jump ahead to the tutorial, please visit our tutorials page: https://github.com/papercup-open-source/tutorials.
Generative models are a very popular topic in the machine learning literature. From Generative Adversarial Networks (GANs) to Variational Auto Encoders (VAEs), it is undeniable that a very big chunk of the papers being published at the top ML conferences (NeurIPS, ICLR, ICML) seem to have some form of generative modelling incorporated into it. They are fascinating, as they can allow us to get a better understanding of the underlying structure existing in our datasets (eg the latent space of a VAE trained on MNIST might cluster per digit). For example, they have permitted, through GANs, generation of extremely high fidelity images which are capable of fooling human beings into believing that they are photos of real people. The list of uses goes on and on.
One particularly interesting subclass of generative models is called flows. They have become popular recently, and have received quite a lot of attention — for example Glow, by OpenAI — because of their immense power to model probability distributions. Flows have been widely used in speech processing, most notably through WaveGlow (NVIDIA), but also more recently by Amazon in this paper. I will not go in depth in explaining what a flow is, since others have done it very well, and I do not pretend to have a better understanding of it than they might. If you are interested in the maths of it, I recommend reading this article, as it is very well explained.
In theory
What I will do, however, is run you through an example of how normalising flows can be used to approximate a very complex probability distribution.
We want to learn an “in-the-wild” distribution implicitly. Note that here, this refers to an arbitrarily complex distribution. Let us assume that we have data sampled from one such “in-the-wild” distribution. For example, this could be handwritten digits (MNIST) or house prices as a function of square footage. We would like to approximate this distribution through generative modeling. In practice, what we will do is to first define a sequence of invertible transformations with upper (or lower) diagonal Jacobian matrices. The motivation for this is the same as stacking multiple linear layers with non-linearities in between in regular neural networks - it allows to model more varied distributions.
Let . We define random variables
Then, I claim the following - given the probability distribution of , and the parametrisation of , for all , we can obtain the probability distribution of . Moreover, since the ’s are invertible, given samples from an “in-the-wild” distribution , we can parametrise it as
where the ’s are modelled as invertible neural networks, and optimise these weights according to the data with maximum likelihood. Easy enough, right? We will give an example of such a distribution in the “In Practice” section.
For more details regarding the math of this claim, please refer to the blog post linked above. If you are interested, I would refer you to the “Change of Variables in Probability Distributions” section in the linked post. The only thing that you need to retain here is that we know the exact probability distribution of , because the ’s are invertible. This allows us to perform maximum likelihood estimation on the weights parametrizing the ‘s. I will however leave you with the formula for the likelihood of according to the above model:
This shows why knowing the probability distribution of (which we do, since we defined it as ), and the determinant of the jacobians (which we do, by design of the transformations ), then we can figure out the exact likelihood of , and can optimise for it. Note that the functions that we have defined are neural networks, and as such are parametrized by weights which we need to optimise in order to find the optimal functions given the “in-the-wild” data.
Even cooler is that once the network is trained, we will have access to a sequence of transformations which allow us to sample from , and through sequential application of the transformations, approximate a sample from any “in-the-wild” distribution. Let us see how we can actually use this in practice.
In practice
This section of the post borrows heavily from a tutorial run by Eric Jang at ICML 2019.
We have adapted it to PyTorch with additional bits here: https://github.com/papercup-open-source/tutorials.
Assume our “in-the-wild” distribution is the very famous “Two Moons” distribution, accessible using the datasets.make_moons function in the package sklearn. If we sample some points from this distribution in 2D-space with 0.05 gaussian noise, it looks like this:

With these techniques, we can take every data point in our data , and using our change of variables formula, compute the likelihood of the data under the distribution of . We can then optimise the weights of the ’s so that the likelihood is maximal given the data. As was described above, the ’s have to take a very specific form, which in this case are picked as RealNVP, which stands for “Real Non Volume Preserving”.
What we end up with is a set of transformations such that , the likelihood of the data under this model, as was defined above, is maximised. Essentially, we have learned an invertible mapping from to whatever distribution follows, and we can now sample from this distribution. We can even get an approximation for the probability density function of this distribution.
Now there are cool things that we can do. Firstly, we can sample from , then apply the sequence of transformations, allowing us to virtually sample from (as per our model). Another way to validate that your model is working properly, beyond the maximisation of the likelihood, is to apply the sequence of transformations from to to samples drawn from the distribution and observe whether we recover the “in-the-wild” distribution (i.e. the ’s). In this case, .
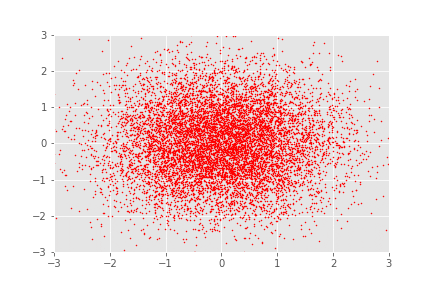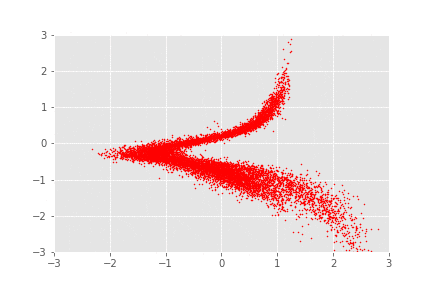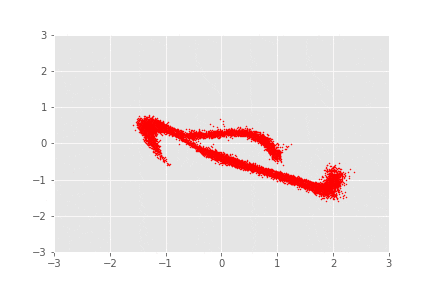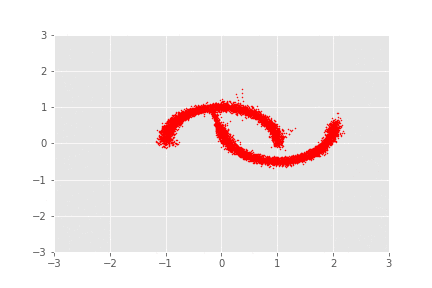
And there you have it. These look like a continuous transformation of samples from to samples from . You can, however, clearly tell that these are just different discrete transformations, with interpolation in between to make it into a nice GIF. It’s interesting, isn’t it, how it almost seems like these transformations look like rotations.
Now why should we care about the fact that these transformations are actually just discrete, and not continuous? What I mean by this is that if we sample , then we can have access to
However, we don’t have access to intermediate representations, eg . In fact, this notation is undefined as of now. What would even be? We’ll see what this means in part 2 of this tutorial.
Subscribe to the blog
Receive all the latest posts right into your inbox